您好Spark爱好者,
流媒体应用程序变得越来越复杂。 当前的分布式流引擎变得越来越困难。
为什么流媒体很难?
- 流计算不是孤立运行的。
- 数据按时间顺序到达是批处理处理的问题。
- 从头开始编写流处理操作并不容易。
DStreams的问题:
- 处理事件时间:处理最新数据。
- 与批处理和交互式互操作流。
- 关于端到端保证的推理。
Apache Spark 2.0添加了新的高级API的第一个版本,即Structured Streaming ,用于构建连续的应用程序。 主要目标是使构建端到端流应用程序变得更加容易,该应用程序以一致且容错的方式与存储,服务系统和批处理作业集成。
结构化流的最后一个好处是该API非常易于使用:它只是Spark的DataFrame和Dataset API。 用户仅描述他们要运行的查询,输入和输出位置,以及可选的其他一些详细信息。 然后,系统逐步运行其查询,维护足够的状态以从故障中恢复,并在外部存储中保持结果一致,等等。
编程模型:
从概念上讲, 结构化流将所有到达的数据视为无界输入表 。 流中的每个新项目就像添加到输入表的一行。 我们实际上不会保留所有输入,但是我们的结果将等同于拥有所有输入并运行批处理作业。
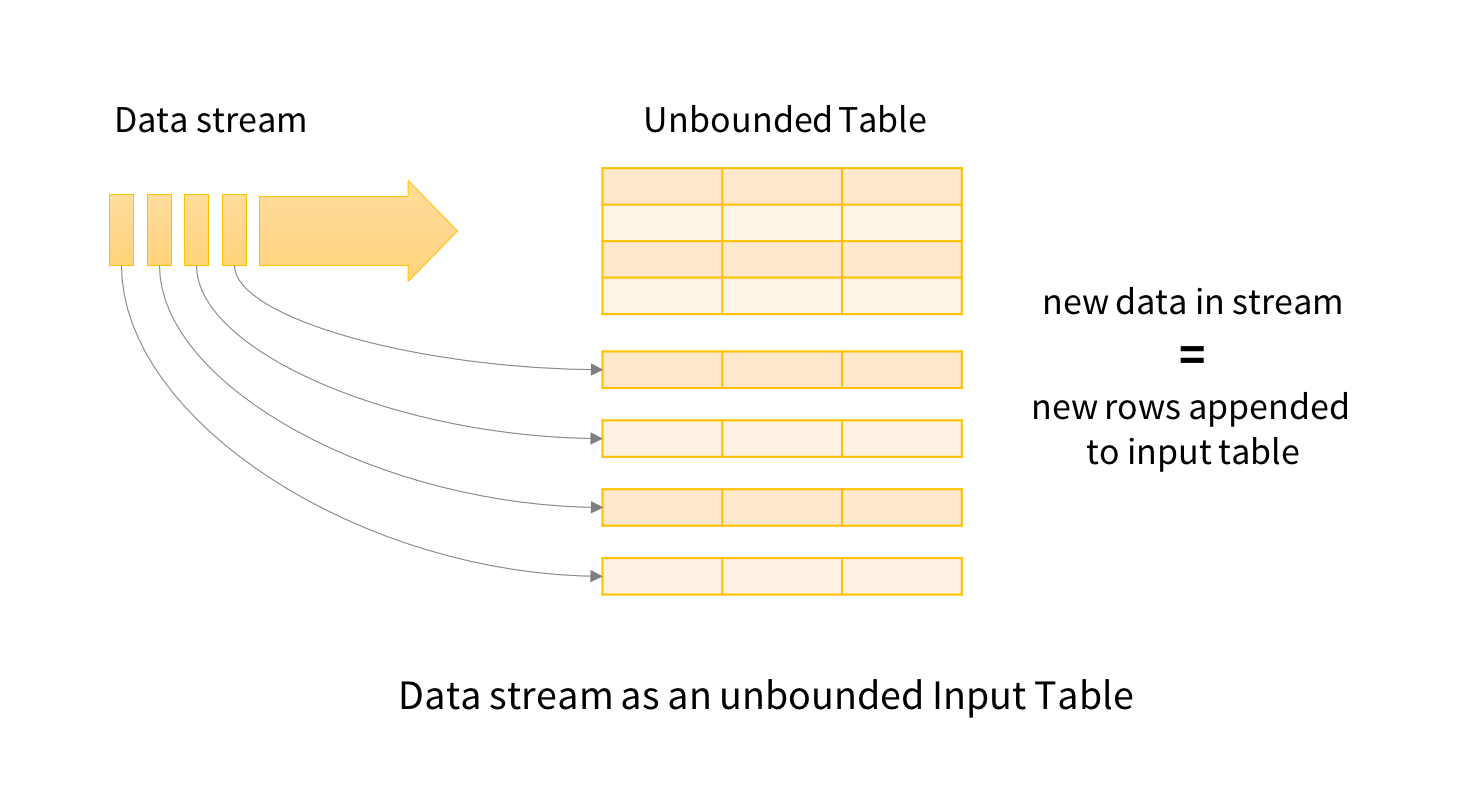
对输入的查询将生成“ 结果表 ”。 在每个触发间隔(例如,每1秒钟),新行将附加到输入表中 ,最终将更新结果表 。 无论何时更新结果表,我们都希望将更改后的结果行写入外部接收器。

模型的最后一部分是输出模式 。 每次更新结果表时,开发人员都希望将更改写入外部系统,例如S3,HDFS或数据库。 我们通常希望增量输出。 为此, 结构化流提供了三种输出模式:
- 追加:仅将自上次触发以来追加到结果表的新行写入外部存储器。 这仅适用于结果表中现有行无法更改的查询(例如,输入流上的映射)。
- 完成 :整个更新的结果表将被写入外部存储器。
- 更新 :仅自上次触发以来在结果表中已更新的行将在外部存储器中更改。 此模式适用于可以在适当位置更新的输出接收器,例如MySQL表。
让我们来看一个例子:
维护从侦听TCP套接字的数据服务器接收到的文本数据的连续字计数。 让我们看看它如何与结构化流一起工作。
让我们一步一步看:
首先,我们必须导入必要的类并创建一个本地SparkSession ,这是与Spark相关的所有功能的起点。
导入org.apache.spark.sql.functions._
导入org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder
.appName(“ StructuredNetworkWordCount”)
.getOrCreate()
导入spark.implicits._
接下来,我们将创建一个流数据帧 ,该流数据帧表示从侦听localhost:9999的服务器接收的文本数据,并转换DataFram e以计算字数。
//创建表示从连接到本地主机的输入行流的DataFrame:9999
val行= spark.readStream
.format(“ socket”)
.option(“主机”,“本地主机”)
.option(“端口”,9999)
。加载()
//将行分割成单词
val单词= lines.as [String] .flatMap(_。split(““))
//产生连续字数
val wordCounts = words.groupBy(“ value”)。count()
这lines DataFrame表示一个包含流文本数据的无界表。 该表包含一列名为“ value ”的字符串,流文本数据中的每一行都成为表中的一行。 请注意,由于我们正在设置转换,并且尚未开始转换,因此当前未接收到任何数据。 接下来,我们使用.as[String]将DataFrame转换为String的数据集,以便我们可以应用flatMap操作将每一行拆分为多个单词。 结果words数据集包含所有单词。 最后,我们通过对数据集中的唯一值进行分组并对其进行计数来定义wordCounts DataFrame。 请注意,这是一个流数据帧,它表示流的运行字数。
现在,我们对流数据进行了查询。 剩下的就是实际开始接收数据并计算计数了。 为此,我们将其设置为在每次更新计数时将完整的计数集(由outputMode("complete")指定)打印到控制台。 然后使用start()启动流计算。
// Start running the query that prints the running counts to the console
val query = wordCounts.writeStream
.outputMode("complete")
.format("console")
.start()
query.awaitTermination()
执行此代码后,流计算将在后台开始。 query对象是该活动流查询的句柄,我们已决定使用query.awaitTermination()等待查询终止,以防止查询活动时退出该过程。
要实际执行此示例代码,可以在自己的Spark应用程序中编译代码,也可以在下载Spark之后直接运行示例。 您首先需要通过使用以下命令将Netcat (在大多数类Unix系统中找到的一个小实用程序)作为数据服务器运行
$ nc -lk 9999
然后,在另一个终端中,您可以通过使用
$ ./bin/run-example org.apache.spark.examples.sql.streaming.StructuredNetworkWordCount localhost 9999
然后,将对运行netcat服务器的终端中键入的任何行进行计数并每秒打印一次。 它将显示如下输出。
# 1号航站楼:
#运行Netcat
$ nc -lk 9999
apache spark
apache hadoop
它将显示如下输出。
#终端2:运行StructuredNetworkWordCount
$ ./bin/run-example org.apache.spark.examples.sql.streaming.StructuredNetworkWordCount本地主机9999
— — — — — — — — — — — — — — — — — — — — — — — — — —
批次:0
— — — — — — — — — — — — — — — — — — — — — — —
+ — — — — + — —-+
| 值|计数|
+ — — — — + — —-+
| apache | 1 |
| 火花| 1 |
+ — — — — + — —-+
— — — — — — — — — — — — — — — — — — — — — — — — — —
批次:1
— — — — — — — — — — — — — — — — — — — — — — —
+ — — — — + — —-+
| 值|计数|
+ — — — — + — —-+
| apache | 2 |
| 火花| 1 |
| hadoop | 1 |
+ — — — — + — —-+
让我们通过上面的示例了解结构化的流模型 :
第一lines DataFrame是输入表,最后wordCounts DataFrame是结果表。 请注意,在流lines框架上生成wordCounts的查询与静态数据框架完全相同。 但是,启动此查询后,Spark将不断检查套接字连接中是否有新数据。 如果有新数据,Spark将运行一个“增量”查询,该查询将先前的运行计数与新数据结合起来以计算更新的计数,如下所示。
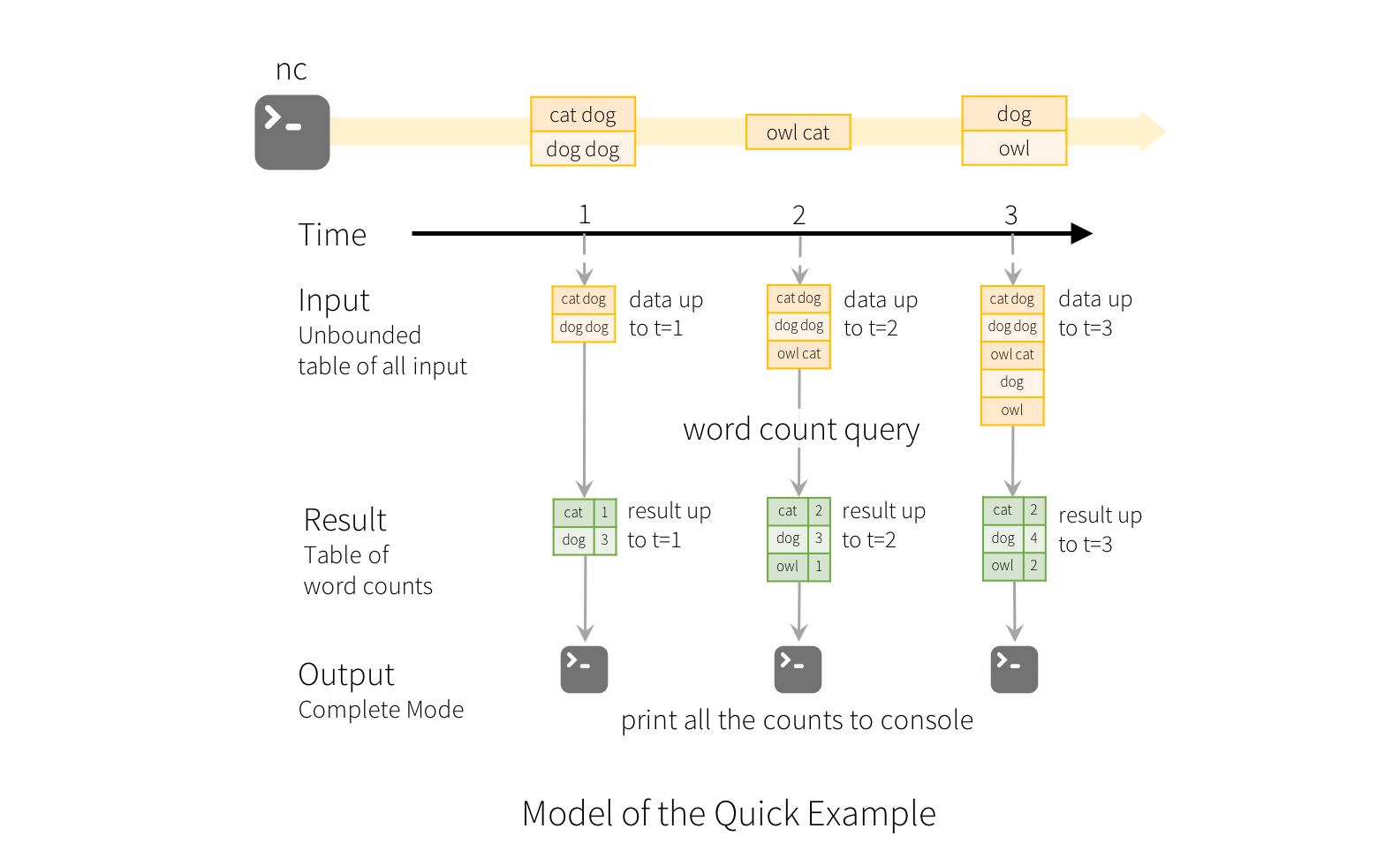
此模型与其他流处理引擎非常不同。 许多流系统要求用户维护状态。 在此模型中,Spark负责在有新数据时更新结果表,从而使用户免于推理。
处理偶数时间和延迟数据:
事件时间是嵌入数据本身的时间 。 对于许多应用程序,您可能需要在此事件时间进行操作。 该模型自然会根据事件时间处理比预期晚到达的数据。 由于Spark正在更新结果表,因此它具有完全控制权,可以在有较晚数据时更新旧聚合,并可以清除旧聚合以限制中间状态数据的大小。 从Spark 2.1开始,我们支持水印功能,该功能允许用户指定最新数据的阈值,并允许引擎相应地清除旧状态。
容错语义:
提供端到端的一次语义是结构化流设计背后的主要目标之一。 为此,假定每个流源都有偏移量(类似于Kafka偏移量或Kinesis序列号)以跟踪流中的读取位置。 引擎使用检查点和预写日志来记录每个触发器中正在处理的数据的偏移范围。
与其他流引擎的比较:
为了显示结构化流的独特之处,下表将其与其他几个系统进行了比较。

结论:
结构化流是基于Spark SQL引擎构建的可伸缩且容错的流处理引擎。 您可以像对静态数据进行批处理计算一样来表示流计算。 尽管结构化流在Spark 2.0中仍然是 ALPHA,并且API仍处于试验阶段。
希望该博客对您有所帮助。 🙂
参考文献:
- https://databricks.com/blog/2016/07/28/structured-streaming-in-apache-spark.html
- http://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
- https://www.youtube.com/watch?v=rl8dIzTpxrI
